
The views expressed in this paper are those of the writer(s) and are not necessarily those of the ARJ Editor or Answers in Genesis.
Abstract
Information is closely associated with life. It is observed in how organisms communicate, how they function internally, and in the technologies they create. Those who claim reality consists of only matter and energy are increasingly misusing the word information to mean purely natural physical behavior since its origin in biology is difficult to reconcile with an atheist worldview. However, their redefined terminology misconstrues the properties and effects of information, restating concepts already explained using physics and chemistry. To address this issue, we introduce a three-dimensional framework to analyze all information-processing systems that includes: 1) Gitt’s five hierarchical layers upon which messages are built: statistics, syntax, semantics, pragmatics and apobetics. 2) The four variants of communication partners, whereby the sender and receiver could each be cognizant or mechanical. 3) Push vs. pull designs, that specify where communication exchange is initiated. This framework defines the scenarios coded information can be used in and prepares the way to address complex questions such as how biological development processes and artificial intelligence technologies seem able to create new information. We argue that misunderstanding the nature and properties of coded information prevents addressing some of the most fundamental questions facing scientists.
Keywords: Materialism; information processing; coded messages; genetic information; biological regulation
Introduction
Information is closely associated with life, both in an organism’s internal processes and also in how organisms communicate. Understanding the essence of information is challenging, given its variety of manifestations. Information is processed by human minds, retrieved from electronic databases, and guides developmental processes during embryology. Are these different kinds of information? Alternatively, what are the shared defining principles?
We have reflected on many difficult questions for decades, such as how information is stored, searched for, and processed in brains; how information is stored and represented in biological cells; and how novel information can be generated from artificial intelligence systems. Our reasoning and explanations prompted us to offer the conceptual framework outlined in this paper. We believe this foundation is necessary before attempting the detailed and complex explanations planned for future publications.
Cells are the core unit of living organisms. Thousands of protein complexes have been identified (Complex Portal 2024), used in cellular processes such as gene expression, manufacture and recycling of biochemicals, assembly of molecular machines, cell differentiation, embryology, etc. Guidance to ensure the correct outcomes is often referred to as information and we will use examples from cellular processes to illustrate the properties of information.
Many details of these cellular processes can be explained using chemical principles, but the explanations using only the properties of matter are almost always insufficient. This would resemble trying to explain the nature and significance, that is, the content, of verbal communication using only the physics of air molecules and human anatomy.
After examining countless cellular processes, an important observation pointing to the existence of information is that virtually everything is regulated. Examples include the amount of each kind of protein to produce and when; its localization within a cell; its assembly with other interaction partners; the half-life of each kind of protein; the number of organelle copies; the number of energy molecules (ATP) produced under different conditions; the activation, sequential processing and regulation of metabolic chains; the duplication and repair of DNA; the translation of mRNA (whether and how often); the recycling of biochemicals currently no longer needed; the responses to environmental changes; etc.
A key principle is that hundreds of cellular programs are rerun repeatedly, relying on processing logic encoded in DNA, RNA, proteins, lipids, and sugars. Each program relies on distinct coding languages (Truman 2012b; 2016a). This is reminiscent of human-designed computer programs that can be reused many times.
Most cellular processes necessary for the survival and replication of cells become comprehensible after identifying the purposes and goals being achieved using information. Reasoning backward from assumed intended outcomes, researchers can retro-engineer how the necessary logic was implemented. This intuition of information driving processes towards a useful outcome also seems to reflect the intuition most laypeople seem to have when referring to information. Information can communicate:
- In a conceptual manner why and how a biological process occurs.
- What is to occur at another location.
- What is to occur at a later time.
Physicist Küppers devoted a career to studying origin of life theories and life processes using principles from biophysics, chemistry, and molecular biology. He recognized that life must be explained as a combination of matter (including energy) plus non-material information (Küppers 1990, 17).
Information as a scientific term seems to have been first used by Hartley in 1928 (Hartley 1928). Soon afterward Norbert Wiener, the founder of cybernetics, had a decisive influence by showing that information is a real entity and worthy of study. He made the often-quoted statement that, “information is information, neither matter nor energy” (Wiener 1948, 1961).
To understand most of what we experience, and the operation of biological cells in particular, one must understand the properties of matter, energy and information. More focus will be on biological cells in this paper. Mental processes are also important but we can’t elaborate on this here.
In this paper, we wish to build on seminal work by others to provide a comprehensive framework for discussions involving information. As discussed below, this will be necessary to address several unresolved challenges.
Careless Use of Information Leads to Confusion
Siemens has emphasized the importance of definitions to ensure clear thinking and avoid contradictions (Siemens 2022; 2023). He noted that even when the same fundamental understanding is shared, subtle differences in how the definition of information is formulated can lead to different answers to the same questions. To illustrate, Shannon and Weaver wrote that (Shannon and Weaver, 1998, 10),
It seems very reasonable to want to say that three relays could handle three times as much information as one. And this indeed is the way it works out if one uses the logarithmic definition of information.
In other words, sending three times more copies of a repetitive message like ABCABCABC . . . would represent three times more information.
Gitt and others consider this a fatal flaw in using Shannon’s work in telecommunications as the basis for understanding information. Shannon’s focus was on the transmission of data with no consideration of its meaning and he never intended to develop a theory of information per se. In any event, Gitt denied that multiple copies of a message provided “more information” (Gitt 2002; 2009). The intuition seems to be that repeating an explanation or providing the same instructions repeatedly, would not create additional understanding nor have any relevant impact.
Although Truman agreed with this reasoning, he pointed out that an attempt could be made to quantify information by comparing the entropy of a system before and after receipt of a coded informational message. Remarkably, from this perspective multiple copies of an identical message could have a different quantitative outcome than only one copy would, as discussed in Appendix A.
Gitt’s Definition of Information
Gitt et al. offered the following definition for a specific kind of information called UI (Gitt 2023, 79):
Universal Information (UI) is a symbolically encoded, abstractly represented message conveying the expected actions(s) and the intended purposes(s). In this context, ‘message’ is meant to include instructions for carrying out a specific task or eliciting a specific response.
This definition resembles one offered by the Merriam-Webster Thesaurus:
The attribute inherent in and communicated by one of two or more alternative sequences or arrangements of something (such as nucleotides in DNA or binary digits in a computer program) that produce specific effects. (Merriam-Webster, 2024)
This is the concept of information mentioned above that is present in cells. However, the inclusion of the word instructions in the definition of Gitt et al. seems to preclude informational messages that are only statements of fact such as:
The loud noise was caused by a book falling off the shelf.
Messages like this one provide understanding and not instructions, but perhaps a response is elicited such as calming someone down and preventing unnecessary activities.
It is not clear whether “conveying” means fully specifying all the details necessary to achieve an outcome. For example, a husband wishes to buy a wedding anniversary present and asks a salesperson the price of some perfume. The message returned, (for example, “It costs $40”) does not provide instructions for carrying out a specific task, namely selecting which present to purchase.
Importantly, a strictly materialist worldview is not consistent with the reality of information in its straightforward sense. We’ll discuss how evolutionists respond to this problem in the following section.
Materialists Reduce Information to Physical Properties
Evolutionists attempt to explain everything in physical terms. Everything in biology is supposed to have arisen naturally with neither planning, purpose nor intelligent guidance (Harrison et al. 2022; Maury 2018; Wong et al. 2016; Yarus, Widmann, and Knight 2009). This poses a dilemma since it seems to contradict the insight noted by Küppers that information is non-physical. An example of how the fundamental nature of information is redefined to circumvent this dilemma can be discerned in a recent review article (Maury 2018) on the amyloid world hypothesis. Maury, a strict materialist, claimed that amyloid-like complexes formed in his laboratory displayed information storage and transfer properties.
This is a remarkable claim, considering that no codes, let alone the genetic code, were present in the complexes synthesized. In addition, Maury claimed his experiments were prebiotically plausible (Maury 2018).
However, we will show that he is misleadingly using the word information. It is incompatible with how cellular programs perform computational logic as demonstrated by numerous researchers (Bray 2011; Dupont and Gonze 2024; Shapiro 2017).
Quoting Maury,
In the encryption process, environmental information is encoded in the three-dimensional structure of the amyloid conformer. The steric information can then be transferred to “daughter” molecular entities through the template assisted conformational replication cycles generating replicas of the spatially altered amyloid conformer. (Maury 2018, 1500)
The words “information” and “encoded” in the quote above contribute no insights; they are merely physical influences, as illustrated in fig. 1. Instead, ambiguity in English has been abused. Chemicals, including amyloids, do change shape (including melting or evaporating) upon absorbing or losing heat. The new shapes can be said to provide “information about the environment,” in the sense that inferences can now be made about temperature changes. Maury is calling the modified shape of amyloids encoding. He argues that additional material absorbed subsequently would adopt the same shape and some fragments could break off. Maury calls these daughter molecules, invoking biological replication.
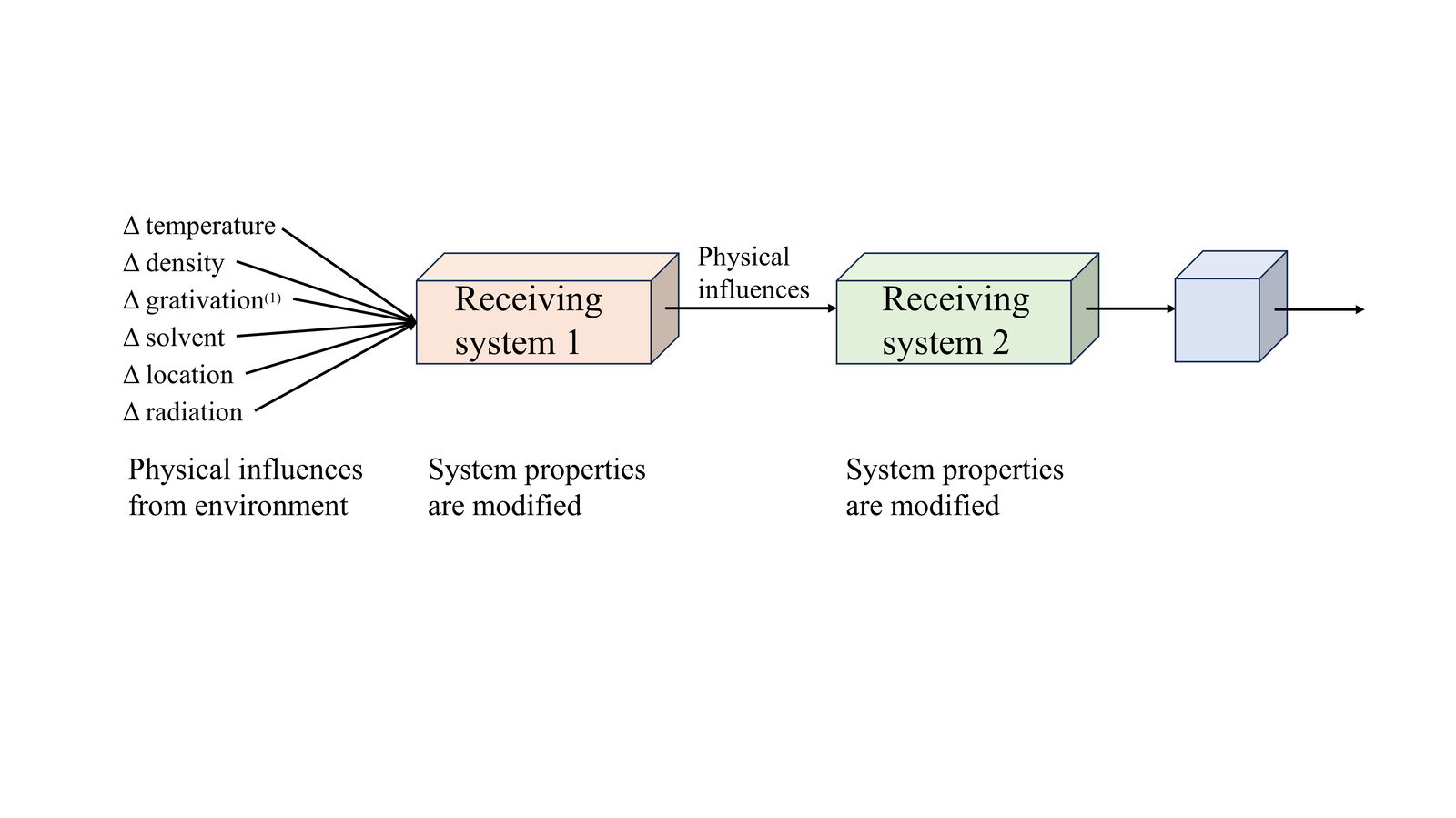
Fig. 1. Physical influences can modify the properties of systems, that can then affect the properties of other systems. (1) For example, laboratory centrifuges.
Terms such as information, encoded, and daughter entities are used in a manner irrelevant to the topic of biological information. Since most readers are unfamiliar with amyloids an analogy will be used to explain what Maury claims. Suppose one finds a collection of written instructions on sheets of paper, encoded using an alphabet of letters. What might be the origin of these instructions? A scientist suggests that temperature changes can change the shape of liquid ink. It could become more or less viscous, droplets might form, perhaps it freezes, or forms a linear trickle. The scientist then claims that the new shapes provide environmental information about the temperature, encoded in the three-dimensional structure.
This explanation misses the point of the original question entirely, namely what was the source of the informational instructions found, the meaning and content of which are unrelated to temperature changes? The fundamental nature of information is that the content and purpose have nothing to do with the properties of the carrier medium (ink in this example). The meaning would be the same if found drawn on the ground without ink or paper at all. Furthermore, if ink found in some physical shape would absorb more ink and later parts would separate, retaining that shape, this is not what replication means in biology. The daughter biological cells include many active processes that ensure that the cells stay alive, relying on a wide variety of different molecules. Neither temperature nor any other environmental factors are the causal factors for the organization of the daughter biological entities.
We submit that the behavior of Maury’s amyloids can be fully described using concepts from chemistry and physics. There is no overlap with the non-material domain of information.
Even though forming amyloids is merely a form of crystallization, many evolutionists accepted Maury’s reasoning. For example, his paper was analyzed in an online video, where one hears,
And ATP is another naturally occurring energy source near hydrothermal vents . . . and once you develop this interaction between amyloids and ATP it’s only a matter of time until you start having refinements into the information storing . . . as well as the creation of protein enzymes to do specific functions. (Based Theory 2023a, 15:30)
The lecturer then claimed that this led to an RNA world followed by DNA-based living organisms. All of this was claimed to be inevitable. If life and information-processing systems are merely physical processes that must inevitably arise, there would be little need for scientific explanations: it’s all only a matter of time.
Surprisingly, this ambiguity in how the word information is used is widely abused by evolutionists (Haig 2021; Varn and Crutchfield 2016). Mathematician Jeffrey Shallit provides an example in a blog posting:
Meyer claims information can only come from a mind. But this is clearly not true. For example, meteorologists collect information all the time about the environment: wind speed, wind direction, precipitation, etc. Based on this information, they make predictions about the weather. But this information did not come from a mind - it came from the environment. (Shallit 2009)
Words are often used carelessly and Shallit made the same mistake as Maury above. To “collect information about something” is a loose way to express that data caused directly by physical properties or behavior was collected to make inferences.
The following sentence serves as an example.
The scientist collected information to understand the trajectory of the planet.
This does not imply that the planet communicated encoded abstract instructions to achieve some goal or communicate understanding.
Another important example of attempts to reduce information to material causes are the stereochemical theories for the origin of the genetic code, explained and refuted in Appendix B.
All the attempts to reduce information to material properties share a fundamental misunderstanding: information is about something and this is unrelated to the physical carrier. Whether written information is communicated using clay, papyrus, parchment, or paper using pigments or indentations is irrelevant. Instead of smoke patterns, Native Americans could have agreed on patterns of arrows shot into the air to communicate messages. And so on. The physical carrier is not what caused the message to be created and its properties cannot explain the encoded meaning. Presumably, materialists would agree that a complete analysis of all the physical properties of computers would be incapable of explaining the origin or meaning of software programs.
As another example, linguists cannot explain the meaning of unknown words by analyzing the physical properties of facial muscles or the sound waves that transport the message.
Claiming that information arises from the matter used to implement it is an example of a Category error (Category mistakes), in the same sense that a painting is not beautiful or ugly because of the properties of the chemicals the pigments are composed of. This misunderstanding is propagated through plays on words that might not be immediately obvious. Here is an obvious play on words to show how a non sequitur results.
We used cranes all summer to work on the building, but now the cranes have flown away.
This illogical double use of “cranes” is easily recognized, since both kinds are readily visualized, unlike “information” that can be rather abstract for a reader.
Digging Deeper into the Nature of Information
Information is used to communicate instructions or understanding between a sender and receiver. This requires the use of a jointly pre-agreed-upon code. Codes are composed of an alphabet of symbols that are abstract, in the sense that they need bear no relationship to the message being conveyed. And a message is composed of a sequence of these symbols (Shannon 1948).
Suppose some scientists were asked to analyze a series of messages where the symbols are distinguishable and don’t follow a predictable pattern. One message might look like this:
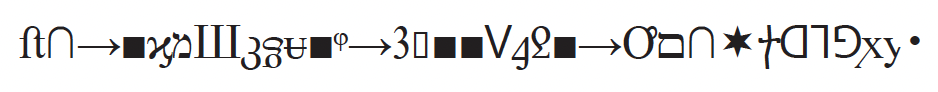 (1)
(1)
If they analyzed the equipment that had generated these symbols using all laws of physics and chemistry, they would be unable to decipher the meaning, outcome, or intent of the message. Why?
Message (1) must indeed be imprinted or carried on a physical medium, but the intended meaning is unrelated to the material substrate. The entire discipline of semiotics (that studies signs and symbols and their use or interpretation) depends on this elementary truth (de Saussure 2011; Peirce 1987). As a rule, the properties of the storage medium should also be stable long enough for the message to be processed as often as necessary. This engineering aspect must be part of the design of the information system.
How might the scientists proceed with message (1)? They could compare the symbol patterns with what occurs after the equipment designed to receive them has processed each message. Ideally, they could conduct experiments by setting up the receiving equipment, generating a variety of symbol patterns, and then analyzing the consequences. As a baseline test, they should generate the same message several times and confirm the same outcome results.
If enough messages are available and processed, some deductions might be possible. For example, perhaps some engineered apparatus is linked to the message-receiving equipment and every time the symbols ∩→ appears the apparatus rotates 180°.
The resulting behavior had nothing to do with the physical attributes of the sending equipment, the message physics, or the material properties of the decoding equipment (Appendix D, Note 1). This is easy to demonstrate. Someone could define a new code. The new instructions might now look something like ■ꓦ instead of ∩→ yet the receiving apparatus still rotates 180°. Alternatively, now ∩→ could be made to generate a different outcome entirely.
Consequently, by definition, codes must be independent of the physical carrier’s properties. Therefore, the physical properties of messages and of the equipment that generated them are not the causal agents of the ultimate (intended) outcomes (Gasiorek and Aune 2018, 24–32; Singh 2000; Stinson 2005).
Some Characteristics of Information by Inductive Reasoning
One can evaluate a variety of examples of information transfer, such as human language, DNA, the bee waggle dance, computer programs, etc. Here are some of our observations:
- A code always exists.
- The distinct symbols comprising the code could be implemented in different ways, such as by shapes, colors, sounds, magnetic spins, voltage levels, etc.
- A physical medium is used to retain the symbol features during their storage and transmission (either as is, or after translating with a code to represent the same meaning in a different way).
- Sometimes sender and receiver remain connected by a message (for example, in analog computing) but not in other cases (for example, in digital computing).
- There are customized interfaces that permit the sender and receiver to interact with messages.
- Sophisticated equipment is used by a sender to express different intended outcomes (which may include having the receiver gain understanding) using sequences of symbols to produce messages.
- Sophisticated equipment is used by the receiver to act upon the intention expressed in messages or to provide understanding to the receiver.
- The intended outcome (which may include having the receiver gain understanding) can be communicated across distance and time.
- The message meaning has no necessary relationship to the properties of the symbols used by the message.
Characteristics like this discredit the claim that information arises through natural processes, along with its storage, retrieval, and transmission. Some materialists like the lecturer in the video mentioned even claim that “refinements of RNA and DNA information storing system are inevitable” (Based Theory 2023b, emphasis added).
Difficult Questions Involving the Concept of Information
Attempts to reduce information to material causes were discussed above. But even correctly recognizing the non-physical nature of information leaves many challenges to formulate universally valid concepts.
For example, a pioneer and leader in information theory has often made the following statement, allegedly having the status of a law of nature:
Universal information can only be produced by an intelligent sender. (Gitt 2009)
This is an important claim that the authors of this paper thought originally seemed self-evident. The difficulty, elaborated on in the following section, is that artificial intelligence systems (that are not intelligent senders in the strong sense Gitt means in his writings1) can generate goal-relevant information. Is the above claim wrong? What is the source of novel, true information when no intelligent sender can be identified?
Another difficult question is whether an intelligence able to generate information must be self-aware.
Another difficult question involves how complex, correct outcomes can be achieved when the sender does not seem to have provided enough details. Recall from the quote above the implication that information had to be produced by an intelligent sender. An example is the mystery of where all the guidance comes from that directs an organism’s development processes (it is not all encoded in DNA). Another example would be how instinctive behavior is encoded, whereby principles or concepts are involved and not all the details. Or the development of fingerprint patterns in the human embryo, that likely involves a biological algorithm, affected by both genetic and environmental factors (identical twins have different patterns, so the final pattern as such is not encoded in their DNA).
Difficult questions like these led to the development of our proposed framework, built upon three dimensions: Gitt’s 5-level hierarchy; communication sender-receiver pairs (whereby both sender and receiver could each be mechanical or consciously intelligent); and push-pull systems defined as which partner initiates a communication.
A Conceptual Framework to Understand Information
Three aspects, or dimensions, will be integrated into a model to explain how information transmitted via messages works:
- Gitt’s five hierarchical levels of information;
- the kinds of sender-receiver pairs; and
- the distinction between push and pull scenarios.
A fuller understanding of information systems also requires including engineering details and other non-message-based resources that collaborate with messages to achieve intended outcomes. These concepts are subsumed under the term Coded Information Systems (CIS) (Truman 2012b).
1. Gitt’s five hierarchical levels of information
The first dimension of our informational message model is Gitt’s five-layer model for information. Different levels are involved during information storage, retrieval, transmission, and implementation of the intended meaning.
Fig. 2 shows the relationship of these five levels with the sender and receiver. These five levels will be introduced next.
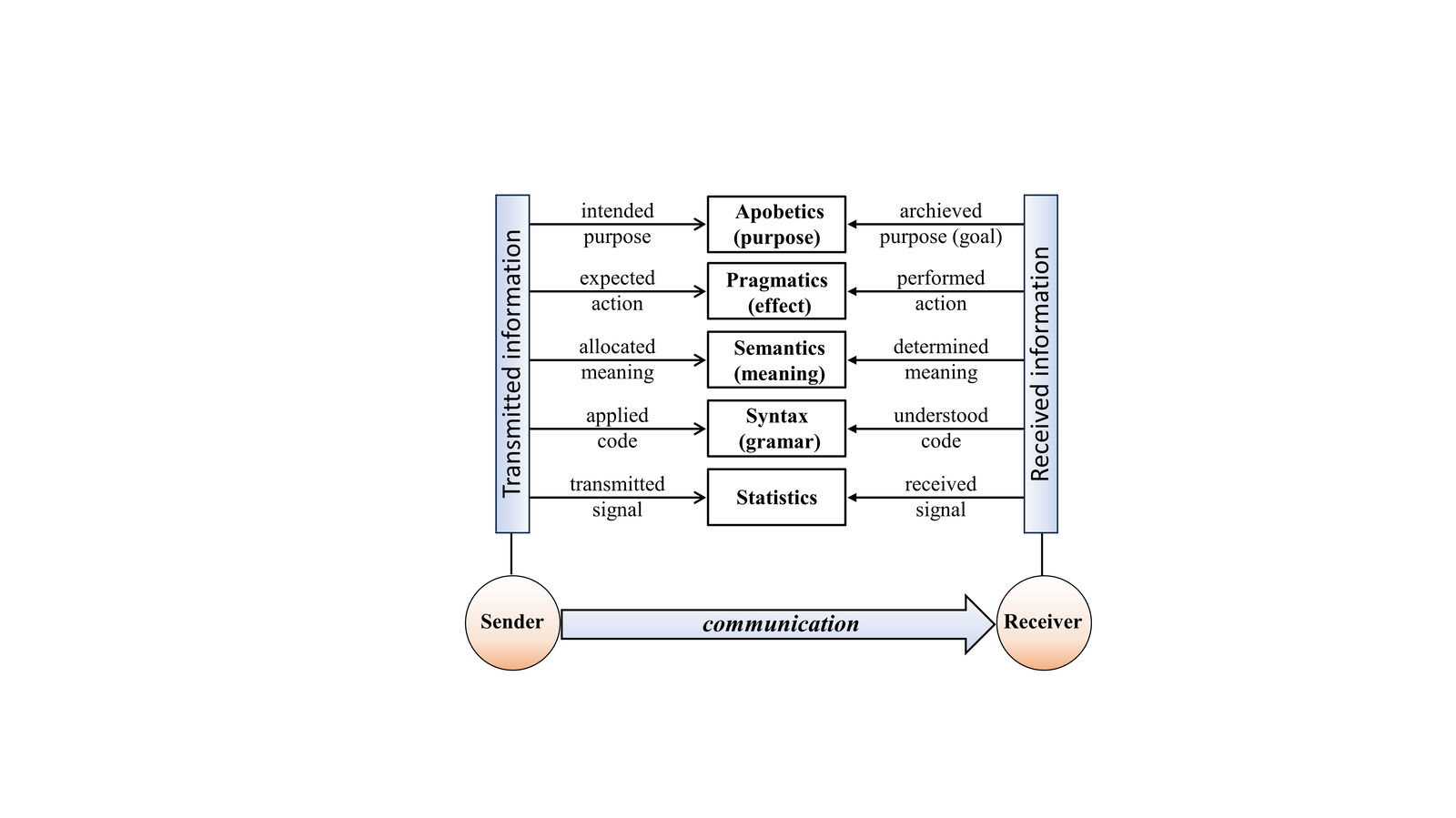
Fig. 2. The five hierarchical levels of Universal Information according to Gitt (Gitt 2023). Redrawn by R. Truman with slight modifications.
Statistics Information in the sense used by Wiener (Wiener 1948, 1961), Gitt, and computer scientists, is communicated through patterns of symbols. These patterns are analyzed statistically for many reasons, such as to design faster, more compact messages; minimize the quantity of material required by the patterns; minimize the computing effort to generate and interpret the patterns; and minimize the damage resulting from corruption of the patterns during storage, interpretation and transmission.
The permissible symbols are defined by a code’s alphabet. Suppose one wishes to create a code to communicate English text. One solution would be to assign a different symbol to every word. The message the big one might now be communicated by for example, × ♠ ■.
This would be cumbersome, requiring many different symbols to be generated, transmitted, stored, and decoded correctly. Another strategy would be to use combinations from a set of symbols that jointly define codewords. Codewords are a unique sequence of symbols that represent something (Togneri and deSilva 2003, 115–118), and are the basis of Chinese writing and Egyptian hieroglyphs. For example, some codewords in the Morse code are:
.- → A
----- → 0
-...- → =
We could also create a code where each word is represented by a decimal number. The same message the big one might now look something like 14 6194 6234 5446.
An improvement would be to rank the frequency of word usage and assign the ones most often used to smaller numbers since smaller numbers require fewer digits. For example,
1 → the
2 → be
3 → to
…
35 → one
…
160 → big
…
The message the big one would now be shorter: 1 160 35. Reflecting further, one might replace decimal numbers by binary numbers. 00 → 1; 01 → 1; 10 → 2, etc. That would simplify the engineering requirements of the storage, processing, and transmission equipment that would now only need to recognize two symbols.
A different strategy to create a code could be to create symbols that represent the sounds (phonemes) used in a language.
Another reason for statistical analysis is that symbols transmitted and stored may require different amounts of effort. For example, suppose the available symbols that could be combined into codewords have very different physical shapes and sizes, such as {•◆∗𠔻}. It would be sensible to create a coding convention that minimizes the usage of the costliest (more elaborate) symbols.
It is remarkable how intuitively most people understand how codes work and how to improve them.
Humans communicate using many codes intuitively such as the smoke signal by Native Americans, or a baseball catcher providing secret hand signal instructions to the pitcher. Specialists do, however, provide important insights that would not occur to most people. The celebrated work in technical communication by mathematician Claude Shannon has been very helpful in developing effective codes. Fig. 3 shows his basic framework (Shannon 1948).
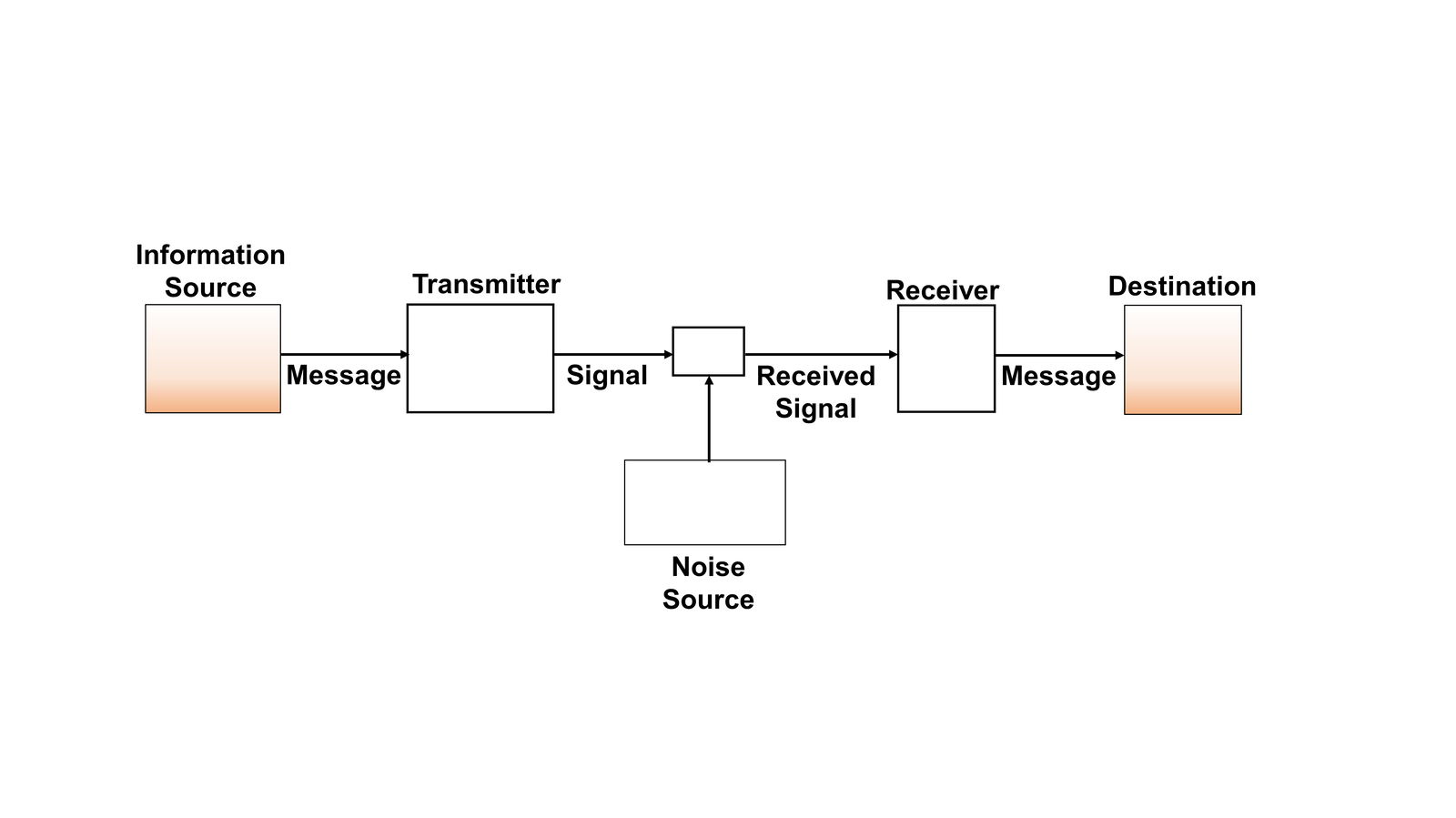
Fig. 3. Schematic diagram of a general communication system according to Shannon (Shannon 1948).
Different goals direct the design of codes. Sometimes maximum compression of messages is a key goal whereas other times providing redundancy to correct errors during transmission or decoding might be more important. We can illustrate the value of mathematical analysis by considering the genetic code. Interestingly, many scientists claim that the genetic code cannot be implemented using fewer than three nucleotides taken together as a codeword, called a codon. This is shown to be incorrect in Appendix C.
Our intention in discussing the statistical aspect of coded information was to emphasize the cognitive effort involved. Nature has no intelligence and knows nothing about goals nor the design tradeoffs of codes. This is an important consideration for those evaluating the hundreds of biological codes used by organisms (Truman 2016a).
Syntax The second level in Gitt’s hierarchy involves the rules established by the code system. In natural and formal languages these rules are called the grammar of a language, and they specify conventions to remove ambiguity. These two sentences do not mean the same thing: the rabbit eats the carrot and the carrot eats the rabbit.
Rules can also be used to correct some kinds of errors. If the next word after the period at the end of an English sentence is not capitalized and separated by a space, then the reader is warned that the received message is somehow flawed.
Syntax also includes aspects like how to delimit codewords. Spaces are used in written languages, time pauses when spoken, fixed lengths for some codes, and other rules for variable length codewords.
Correct syntax is not an aspect of physics or chemistry. However, the biochemical equipment that processes biological codes such as the histone-, splicing-, ubiquitin-, and gene regulatory code (Truman 2016a) must be designed to recognize the correct syntax of that particular code. Biological codes must be processed by biochemical machines designed to avoid errors by taking code syntax into account.
Semantics Sequences of symbols and syntactic rules are prerequisites for messages that have meaning. The following messages have meaning.
C2 = A2 + B2
(2)The window is dirty
(3)var total = calcPrice(price, taxRate);
(4)The following string might have meaning. It depends on whether communication rules have already been established.
24cv β–β–β kl$4
(5)Meaning is indispensable if an intended outcome (the next level, pragmatics) is to be achieved. This poses dilemmas many materialists recognize and associate with information. For example, DNA sequences have been encoded to represent protein amino acid sequences that are to be constructed. The first dilemma is that these meanings had to be stored somehow in DNA. Secondly, additional biochemical equipment (RNA polymerase) must be capable of generating the correct mRNA sequences to produce the current proteins when needed. Thirdly, an independent machine (ribosome) must be capable of correctly interpreting and processing the intended meaning transferred to the mRNA. But meaning is an abstract representation of something and not based on intrinsic material properties.
Pragmatics (Greek action, doing). An information-containing message produces some effect on the receiver. Here is an example of a message sent to a non-cognizant receiver:
T1 <- 30;
(6)Here is an example of a message sent to a cognizant2 receiver:
Please adjust the temperature to 30 °C;
(7)An intelligent agent can generate and send messages, so usually one thinks the expected effect is initiated and determined by the message sender. But this is not always the case, which is why our framework to interpret information includes other dimensions besides Gitt’s 5-level model. A non-cognizant machine could also generate and send coded messages in response to pre-programmed logic. However, the outcome would be determined now by the receiver who elicited the message for some purpose and decides what to do with the message received. Here is an example.
Suppose a driver wants to decide whether to stop at a motel or continue driving. He asks a person or a machine what time it is (that is, “pulls” a message) and makes a decision based on the answer. The sender of the message did not communicate whether to stop or to continue driving, it was the receiver that decided.
We will see below that sometimes during a series of communication exchanges the role of the sender and receiver changes.
Apobetics (Greek = result, consequence). The highest layer refers to the purpose or intended goal of a message. Expecting a purpose to lie behind messages transmitted seems reasonable. After all, why would the elaborate equipment and codes have been set up? The ability to communicate goals permits outcomes to be specified at other locations and future times, thereby projecting the will of an intelligent agent.
2. Four variants of message-exchanging partners
Another dimension in our framework involves the message-exchanging partners. There are message senders and recipients. Either could be cognizant, that is, sentient and self-aware. This is related to the concept of intelligence. Alternatively, either could be pre-programmed machines.
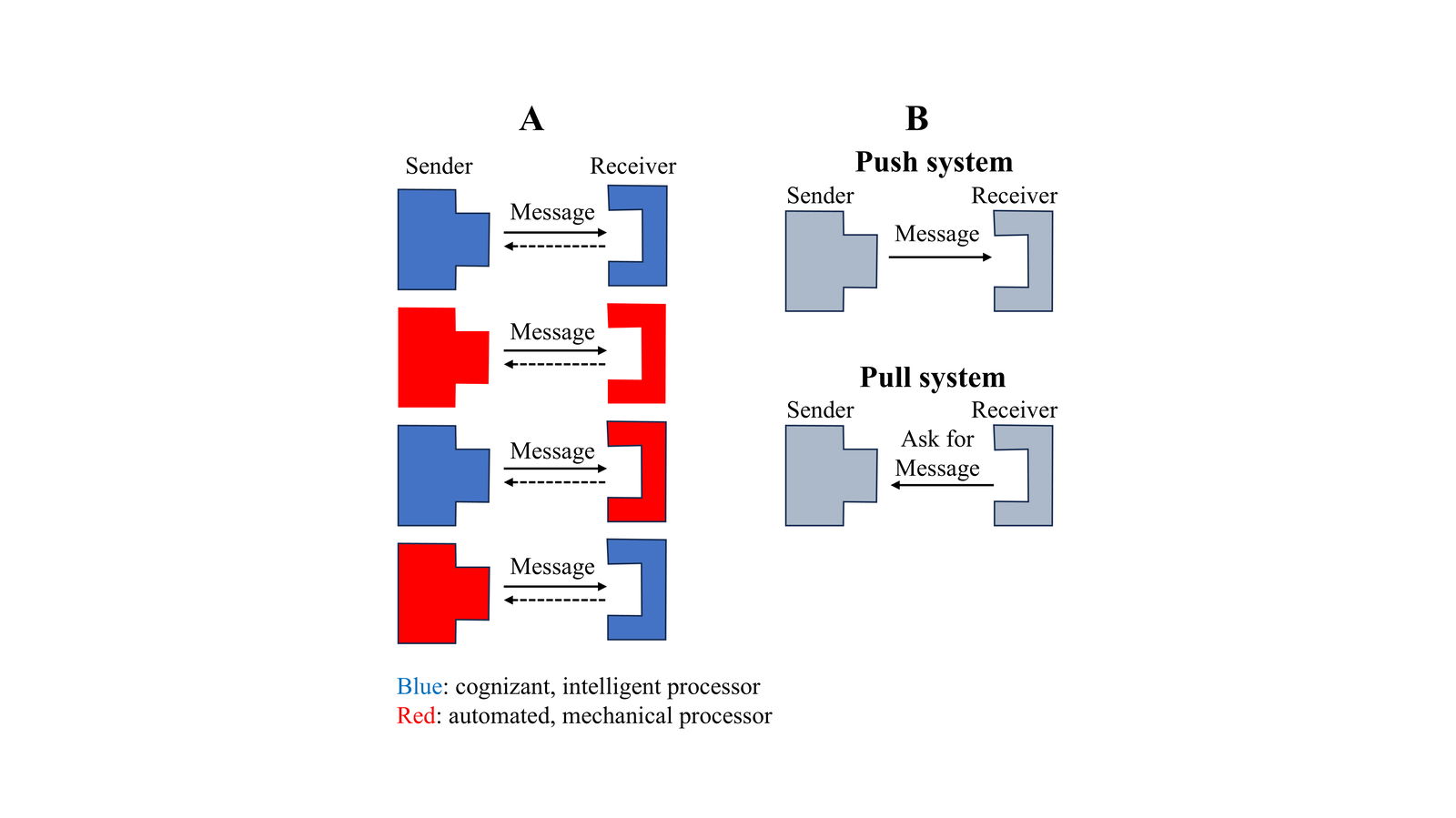
Fig. 4. A: The four variants of communication partners that can exchange messages. B: Push versus pull information systems. Pure push systems initiate generation and sending of messages. Pure pull systems deliver messages based on data provided by a receiver.
As illustrated in fig. 4-A, this leads to four variants of message-exchanging partners:
1. Cognizant sender with cognizant receiver. The key example is when two people converse.
2. Automated sender with automated receiver. An example is when process control systems interact. Sensors can be used to determine conditions like temperature, pressure, chemical concentrations, and so on. Logic processing is carried out using programs already installed, and then the appropriate coded messages are sent to receiving equipment to communicate what is to be adjusted. There are variants for how the sender could operate. Sometimes the sender executes preestablished sequences of processes (like collecting data from sensors periodically). Another variant is for the sender to wait until activated by an alarm.
3. Cognizant sender with automated receiver. For example, a person giving instructions to virtual assistants.
4. Automated sender with cognizant receiver. For example, a car navigator giving audio instructions to a driver.
3. Push versus pull information systems
Information systems can also be categorized as push and pull systems, as shown in fig. 4-B. This refers to which partner initiates the communication exchange. This often needs to be considered to understand the four variants of partners.
1. Push systems. Pure push systems initiate the transmission of messages and also determine the content. This includes examples like television programs, books, lectures, and news delivered as a screensaver. Sending marketing information about products to a distribution list of recipients is a push system. Those who think that DNA contains the blueprint for an organism are implying that DNA is acting like a pure push system that sends out instructions. An aspect of push systems is that sometimes receivers could refuse to accept a message.
2. Pull systems. Pure pull systems initiate the communication and influence the content to be extracted. Data, facts, rules, equations, and so on can be stored in an extractable manner on a storage system. The receiver then sends a message that communicates what is to be extracted. An example would be an SQL query sent to a relational database or a question posed to an artificial intelligence system.
Many information systems are not pure push or pull systems and can both initiate or provide informational messages.
Discussion
Must all Gitt’s five layers be observable to infer information transfer?
According to Gitt (Gitt 2009),
Information is always present when all the following five hierarchical levels are observed in a system: statistics, syntax, semantics, pragmatics and apobetics.
In his view,
The apobetics aspect of information is the most important one, because it inquires into the objective pursued by the transmitter. (Gitt 1996)
But can objectives always be observed? Messages rarely if ever fully communicate this explicitly, so intended objectives generally must be deduced.
Siemens has opined that needing to observe a goal is too strong and an unnecessary requirement to confirm the existence of information. He suggests that a reasonable implication would be sufficient (Siemens 2022; 2023). He pointed out that whenever the three lower levels of statics, syntax, and semantics have been confirmed in a message, people inevitably assume pragmatics and apobetics exist. In fact, the existence of only the lowest or sometimes two lowest levels is considered sufficient in the SETI (Search for Extraterrestrial Intelligence) projects that analyze patterns of extraterrestrial electromagnetic radiation (Morrison and Cocconi 1959). Should someday the lower levels be confirmed, it would be assumed that information had almost certainly been sent by a sentient intelligence for a purpose, such as letting others know they exist (apobetics). Perhaps instructions may even have been sent (pragmatics).
The hierarchical layers clarify that a mere response to a physical input such as the expansion of a gas upon absorption of heat is not information. This can be recognized by the absence of a code. Linking pressurized gas to perform some kind of work, like moving a piston could be used as part of a machine, but this is not information. Condensation of molecules to form crystals is also not an example of information, nor is a physical interaction of amino acids, nucleotides, or other molecules with amyloids. These are merely well-understood chemical interactions that do not communicate any goals.
Analysis of cognizant communication partners
The message exchange framework can be used to describe human conversation. Consider the following exchange:
Nancy: “Have you acted on the bad news from the Middle East?”
George: “Not yet, I’m waiting for your thoughts.”
Nancy: “Get rid of as many as fast as you can.”
This exchange requires other resources to be applied, such as context and prestored knowledge. Here Nancy is an investor and George is her stockbroker. Of Gitt’s five levels, statistics, syntax, and semantics levels are recognizable. Both have certain stocks in mind so the messages exchanged need not mention them. Nancy first plays the role of a message sender that pulls data from George. Initially, George is the receiver, but by responding with more than “No” now becomes a sender who is attempting to pull data from Nancy. In the third exchange, Nancy, having first received a message, now sends a message with minimal instructions. By assuming her partner is cognizant and can reason, she relies on him to deduce the appropriate actions.
How does this cryptic exchange work? Before formulating her instructions, Nancy reasoned at the top (apobetics) layer what her goals were and then dropped down to the pragmatics layer to reason what would be necessary to achieve her goal(s). Siemens addressed this insight by emphasizing the role of a will in information exchange (Siemens 2022; 2023). Semantic and syntactical skills were then used to produce Nancy’s final message. Remarkably, Gitt’s five layers, sender-receiver pairs, and push-pull activities can occur within a single mind; the roles can be reverted during internal communication (reasoning). Multiple exchanges can be involved that clarify and refine what is to be communicated.
As a general principle, intelligent agents make assumptions about how their partner would leverage the semantic content provided to them with reasoning at the pragmatics and apobetics levels. These assumptions precede and influence the details of the message to be generated and sent.
Analysis of automated communication partners
The example above involved a cognizant sender and receiver. DNA can be used to illustrate a different scenario, namely how automated (non-cognizant) communication works. Gitt’s layers are present or implied in the messages used by DNA to communicate with RNA polymerase, whereby DNA acts as a sender (it instructs to form a specific primary RNA sequence). Since it initiates the action to be performed by the RNA polymerase, it appears to act as a push system. But DNA is also used differently. When DNA should produce RNA is communicated by different regulatory codes (Anonymous 2018) and also depend on Gitt’s layers. But now DNA acts as a receiver of messages in the form of transcription factors. Special nucleotide sequences called cis-factors query the environment for transcription factors, so now DNA is acting as a pull system.
Several other communication codes located in DNA are known collectively as epigenetics (Tollefsbol 2022). Different codes are also used to identify and repair damaged regions of DNA (Boiteux and Jinks-Robertson 2013) by communicating with the repair complexes. Noteworthy also is that DNA sequences are converted into other codes located on proteins that specify the half-life of the protein using the ubiquitin code (Liu et al. 2021). Other DNA sequences are converted into codes that specify where to transfer a protein in the cell, called signal peptides (Teufel et al. 2022).
A multitude of other cellular processes are regulated by automated communication. These are usually integrated with other processes to produce complex outcomes. Examples include the highly regulated cell cycle (Vermeulen et al. 2003); differentiation into hundreds of cell types (Nelson 2022); production of different tissue types; production of organs; repair of damaged body parts; etc.
Considerations on the four variants of message-exchanging partners
There are many scenarios of informational message exchanges based on the nature of the sending and receiving partners. Mind-body interactions imply that a cognizant sender provides messages with a mechanical receiver. What about when organisms send messages to attract a mating partner (for example, pheromones); does this involve cognizant or mechanical senders and receivers? The correct answer, as usual in biology, is “it depends.”
It seems worthwhile to comment on the four kinds of communication partners to provide insights and to clarify why cognizant vs. non-cognizant needs to be distinguished.
1. Cognizant sender with cognizant receiver. In this scenario we’ll assume that a back-and-forth conversation occurs. The role of sender and receiver could revert many times. To some extent the receiver will interpret the actions (pragmatics) of the sender and attempt to deduce his goals. The receiver then reflects on his own goals, and prepares a message crafted to manipulate the reasoning process of their partner while implying his own goals. Therefore, a message implies additional things a cognizant receiver is expected to surmise. If the sender initiates the conversation it is acting as a push system, but if eliciting information it is acting as a pull system.
Skilled debaters and politicians are experts at anticipating and counteracting what opponents will say before uttering their messages to optimize achieving their own goals. Clever tactics can be employed to mislead listeners such as to “take literally” what their opponent said despite knowing that this was not the intended meaning. Statements can also be “twisted” to deliberately mislead.
Cognizant communicators have a deep understanding not only of the goals of their partners but also of their abilities and skill levels. These are taken into account when formulating messages. How these thinking processes work in detail is a mystery, and inanimate matter does not possess the properties necessary to generate such behavior.
2. Automated sender with automated receiver. In this setup we’ll assume that different messages will need to be sent to the receiver, based on signals the sender receives from sensors or based on a preplanned schedule. Fixed messages could have been prepared or messages could be generated by a software program. The purpose of generating the various messages must be known in advance by the system’s designer to ensure relevant messages will be sent since the sender and receiver are unaware of any goals. Familiar technical examples of this communication variant include: a chemical process control system; a warehouse robot with an inventory management system; and a smart thermostat with an HVAC system.
When the sender always initiates the communication (for example at fixed times or in response to a signal from a sensor) this is a push system design. Alternatively, when the receiver evokes a message (sometimes providing parameter values) the sender acts as a pull system.
Analog computing is used in cells (Appendix D, Note 3) and therefore uses no source code (Singh, Borger, and Truman 2025). In analog computing, physical interactions participate directly in the processing of logic. In cells, messages are used to communicate between a sender and receiver, and the communication occurs at the interface where interaction occurs (Singh, Borger, and Truman 2025). For example, transcription factors act as messages, whereby only a small portion is recognized by the cis-factor receiver (that is, at the interface). After the transcription factor binds to the cis-element the rest of the transcription factor communicates the rest of the message. This involves physical interactions with other biomolecules to produce the intended outcome.
Examples of complex two-way communication in cells are gene regulatory networks and neurotransmission between neurons with feedback loops.
Information processing within and between biological cells is readily identified in the literature by the words code and program. Other examples of automated communication in biology include reflexive flight when a fly senses a rapid movement; human coughing; sneezing; the gag reflex; and the withdrawal reflex (upon touching a hot surface your hand quickly pulls away before you realize what happened).
Materialists face the dilemma that automated communication systems anticipate specific outcomes to be achieved and rely on messages whose functioning demands elaborate hardware.
3. Cognizant sender with automated receiver. In this setup, the intelligent sender is aware of its goals. He or she creates a message with instructions using a preestablished language, being aware of the capabilities of the receiving equipment. (For example, one does not ask Siri to buy a winning lottery ticket). Examples include: using chatbots for customer support; making database queries or asking questions to artificial intelligence systems; using speech-to-text software or a language translation system; giving commands to virtual assistants; and inputting mathematical expressions into a software calculator.
4. Automated sender with cognizant receiver. In this setup, the goal(s) to be achieved by the messages must be known by the designer of the automated communication partner. The messages could be static or configurable. Examples include: subscription renewal alerts or bill payment reminders; smart home security alerts in response to a sensor signal; a fraud detection email based on suspicious activity; low inventory alert in a retail business; server status alerts sent to an administrator; and extreme weather warning alerts.
The intended receiver may not have expected these kinds of messages (like an unusual alarm), but the designer could assume he or she would deduce the intention and act correctly.
Push, Pull, and Interactive Information Systems
In many cases, a device can engage in interactive exchanges of messages, and thus not be part of a pure push or pure pull design. Cognizant communication partners, like people, often exchange the role of push and pull during a conversation and influence the communication. In other setups, the options can be constrained. For example, a device to play music could have the acoustic details already prepared, and the target recipient may be limited to deciding when and what music is to be played, how loudly, etc.
As mentioned above, DNA serves as both a push and a pull source of messages for many programs.
Database and artificial intelligence systems usually have a pull character. Typically, an interface language is provided through which users express what they want to know. The queries posed can influence how the algorithms process in manners not anticipated by the system designer. The consequence is that the messages pulled can be jointly influenced by the system designer(s) and the user. The goal (apobetics) when designing the system may have been to earn a profit by providing a service. The content of the individual messages generated need not have been known or anticipated by any intelligent agent. This does not necessarily contradict the claim that “information can only be produced by an intelligent sender” (Gitt 2009, 100) but analyzing this will be deferred to a future paper.
In some scenarios, system designers intend to manipulate behavior. Therefore, the messages will be analyzed and blocked or modified using preprogrammed rules to be “politically correct” before being delivered.
Engineering Components to Leverage the Effect of Messages
Where is all the guidance coming from to regulate cellular behavior? Clearly, not only from gene sequences (Ball 2024). This was the primary concern that prompted reflections organized under the rubric of Coded Information Systems (CISs). Key notions are the concepts of additional resources and goal-directing refinement processes (Truman 2012b) as shown in fig. 5. In the case of cognizant senders and receivers, additional resources include accessible stored knowledge, reasoning abilities, and associations called context. In the case of automated (non-cognizant) communication partners engineered constraints play an important role. For example, in cells, enclosed compartments enhance some chemical processes while preventing the wrong ones from occurring (Truman 2012b; 2013; 2016b). Another phenomenon involves emergent effects. For example, proteins fold into precise shapes (Rumbley et al. 2001) that permit specific portions to interact precisely with only their intended biochemical partners to achieve an intended outcome. We are currently analyzing another kind of cellular resource reminiscent of a family of techniques from computer science known as metaprogramming. One example involves gene regulatory networks (Anonymous n.d.) in which gene products called transcription factors activate and deactivate other genes concurrently. This leads to a form of logic processing that is not coded directly in DNA.
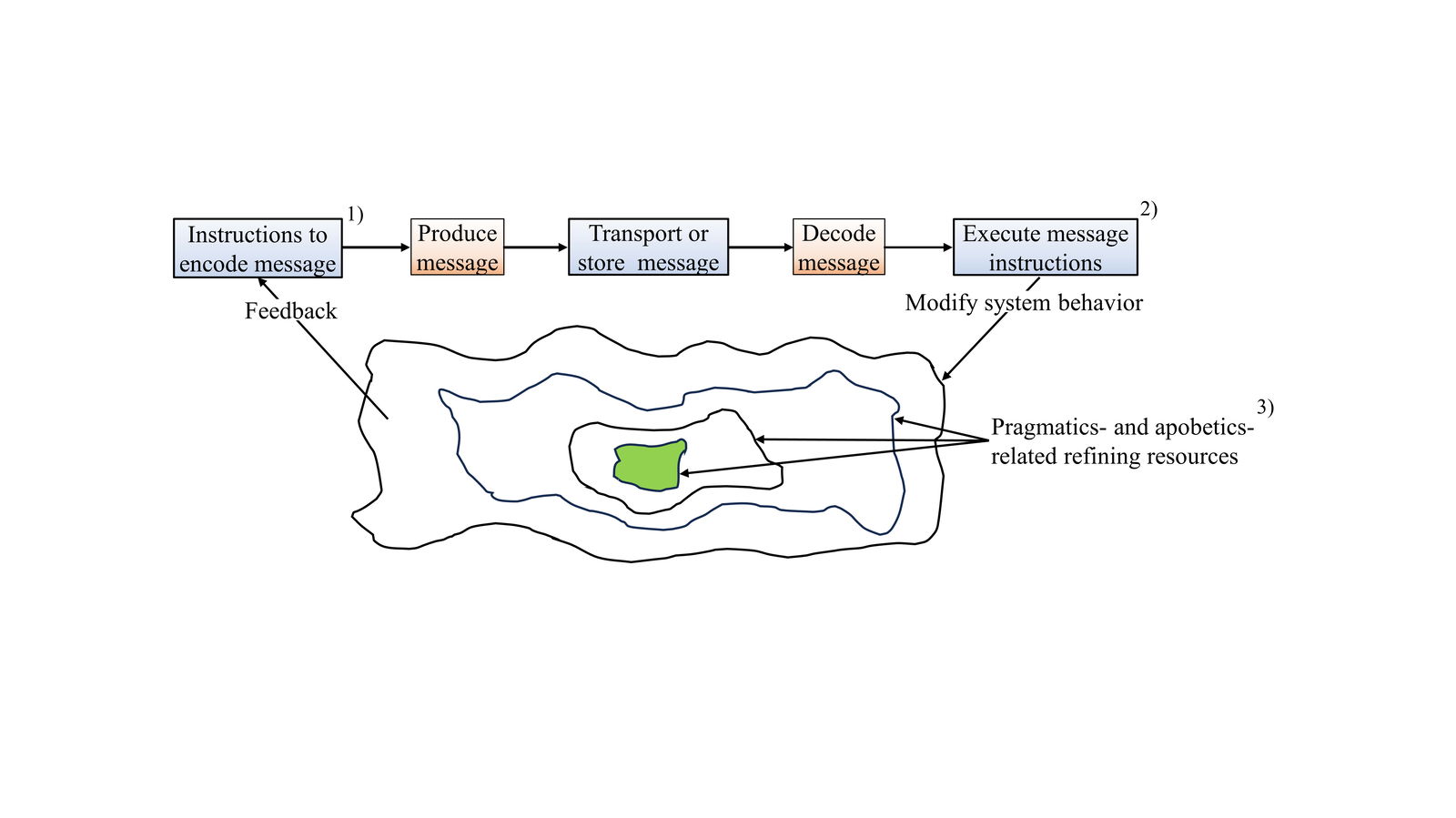
Fig. 5. The instructions or knowledge provided by coded messages can be enhanced through several refining resources to achieve the intended goals (Truman 2012b).
1. Intentions must be conveyed using informative messages.
2. The message-decoder is linked to tailored equipment that can act upon the instructions. The outcome could be physical or cognitive processes, depending on whether the receiver is cognizant or automated (mechanical).
3. Refining resources are other factors that guide towards intended pragmatics and apobetics (Truman 2012b; 2013; 2016b).
Conclusions
Information processing is intimately associated with life and is the key to understanding how organisms develop, adapt, meet their ongoing material and energy needs, and reproduce. We have shown that information is neither energy nor matter but nevertheless, a real and important entity used to achieve goals across time and distance.
The correct research questions will not be asked if fundamental aspects of information are ignored. These include recognizing that information communicates how to achieve intended goals at other locations and times using special messages; and that complex technology is needed to generate, store, transmit, and interpret these messages. As an example, it is sensible to first recognize that various goals need to be fulfilled in cells that require specific processes to be executed. The processes that enable these can include synthesizing the right proteins in the correct amount, at the right time, and location. Based on this insight, a researcher can begin searching for how information ensures these outcomes.
Materialists in general often attempt to redefine information since it does not fit into their worldview. This is detrimental since it prevents studying biological processes at an effective, conceptual level. Using strictly physical explanations merely regurgitates irrelevant details. To illustrate, scientists would not attempt to understand the language of whales by analyzing their physiology or the movement of water molecules.
Degrading information to mere physical processes and claiming that it is only a “matter of time” for an information storing system to arise naturally (Based Theory 2023a, 15:30) is a science killer. Anything inevitable does not inspire extensive research effort.
This paper is intended to provide an introductory overview of three sets of tools to help understand information, specifically the message exchange part, especially in biological systems: Gitt’s five hierarchical levels in information, the kinds of partners involved in message exchange, and the distinction between push and pull designs of message generators. Information interchange often involves multiple interactions between the communicating partners who alter roles to clarify and provide new insights. In addition to informational messages, we have referred to concepts comprising a model called Coded Information Systems (Truman 2012b). The intuition is that in addition to messages, guidance can also be provided to achieve goals by engineered components that constrain outcomes.
These tools should help examine the significance of artificial intelligence systems that combine input from many intelligent agents working independently, enhanced by self-learning algorithms. Other questions can also be examined such as whether a cognizant agent must be involved for information to be produced; why it has not been possible to extract measures of value from encoded messages; and how analog computing principles are used in cells.
An unanswered dilemma is how so much more gets accomplished sometimes than is communicated by the instructions coded on some messages. An example is the question of where all the instructions come from for the development processes that produce a multicellular organism from a fertilized cell. Biologists do not believe these all are encoded directly in DNA (Ball 2024). We hope to provide some insights in future papers and these build on the three dimensions outlined in this paper.
Acknowledgements
We are very grateful for valuable feedback provided by two anonymous reviewers, and in particular to Dr. Carl Wieland for numerous discussions and his critical analysis of a previous version of this paper.
References
Anonymous. nd. “Gene Regulatory Networks Articles Within Nature Communications.” https://www.nature.com/subjects/gene-regulatory-networks/ncomms. This is a continually updated list of papers on gene regulatory networks.
Anonymous. 2018. “Modes of Transcriptional Regulation.” Nature Reviews Genetics. https://www.nature.com/collections/pfdsgqgzck This is a continually updated collection of papers dealing with gene regulation.
Ball, Philip. 2024. How Life Works: A User’s Guide to the New Biology. London, United Kingdom: Picador.
Baranov, Pavel V., Maxime Venin, and Gregory Provan. 2009. “Codon Size Reduction as the Origin of the Triplet Genetic Code.” PLoS ONE 4, no. 5 (May 27): e5708. doi:10.1371/journal.pone.0005708.
Based Theory. 2023a. “Amyloid World Hypothesis: The Origin of Life|Abiogenesis.” https://www.youtube.com/watch?v=Zaz3OXthHlg.
Based Theory. 2023b. “Amyloid World Hypothesis: The Origin of Life | Abiogenesis.” Uploaded May 12, 2023. https://www.youtube.com/watch?v=Zaz3OXthHlg Starting at 14:02: “As that happens the amyloids that are more stable will stick around for longer than the ones that are less stable and will continue to incorporate new amino acids and elongate themselves”. Actually, the more stable amyloid fibrils become insoluble. The way the experiments were designed only artificially activated amino acids would add that matched the missing positions in the designed longer templating peptide; they don’t just “continue to incorporate new amino acids”.
Boiteux, Serge, and Sue Jinks-Robertson. 2013. “DNA Repair Mechanisms and the Bypass of DNA Damage in Saccharomyces cerevisiae.” Genetics 193, no. 4 (April): 1025–1064.
Bray, Dennis. 2011. Wetware: A Computer in Every Living Cell. Yale New Haven, Connecticut: University Press.
Category Mistakes. Stanford Encyclopedia of Philosophy. https://plato.stanford.edu/entries/category-mistakes/
Complex Portal. 2024. https://www.ebi.ac.uk/complexportal/home.
de Saussure, Ferdinand. 2011. Course in General Linguistics. Translated by Wade Baskin. New York, New York: Columbia University Press.
Dupont, Geneviève, and Didier Gonze. 2024. “Computational Insights in Cell Physiology.” Frontiers in Systems Biology 4 (13 March). doi: 10.3389/fsysb.2024.1335885.
Gasiorek, Jessica and R. Kelly Aune. 2018. Message Processing: The Science of Creating Understanding, chapter 4. Mānoa, Hawai’i: University of Hawai’i OER.
Gitt, Werner. 1996. “Information, Science and Biology.” Creation Ex Nihilo Technical Journal 10, no. 2 (August): 181–187.
Gitt, Werner. 2002. Am Anfang war die Information: Digitalisierung als Religion. Holzgerlingen, Germany: Hänssler Verlag.
Gitt, Werner. 2009. “Scientific Laws of Information and Their Implications—Part 1.” Journal of Creation 23, no. 2 (July): 96–102.
Gitt, Werner. 2023. Information: The Key to Life. Green Forest, Arkansas: Master Books.
Haig, David. 2021. “A Textual Deconstruction of the RNA World.” Biosemiotics 14: 651–656.
Harrison, Stuart A., Raquel Nunes Palmeira, Aaron Halpern, and Nick Lane. 2022. “A Biophysical Basis for the Emergence of the Genetic Code in Protocells.” Biochimica et Biophysica Acta, Bioenergetics 1863, no. 8 (November 1): 148597. doi: 10.1016/j.bbabio.2022.148597.
Hartley, R. V. L. 1928. “Transmission of Information.” Bell System Technical Journal 7, no. 3 (July): 535–536.
Küppers, Bernd-Olaf. 1990. Leben = Physik + Chemie? Das Lebendige aus der Sicht bedeutender Physiker. 2nd ed. Munich, Germany: Piper-Verlag.
Lesne, Annick. 2023. “Molecular Codes in Biology: The Genetic Code and Beyond.” HAL open science, hal-04085620 . https://hal.science/hal-04085620/document.
Liu, Cui Hua, Yu Rao, Daming Gao, Lixin Wan, and Lingqiang Zhang. 2021. “Editorial: Ubiquitin Code: From Cell Biology to Translational Medicine.” Frontiers in Cell and Developmental Biology 28, no. 9 (28 October): doi.org/10.3389/fcell.2021.791967.
Maury, Carl Peter J. 2018. “Amyloid and the Origin of Life: Self-Replicating Catalytic Amyloids as Prebiotic Informational and Protometabolic Entities.” Cellular and Molecular Life Sciences 75, no. 9 (March): 1499–1507.
Merriam-Webster. 2024. “Information.” Merriam-Webster Thesaurus. https://www.merriam-webster.com/dictionary/information.
Morrison, Philip, and Giuseppe Cocconi. 1959. “Searching for Interstellar Communications.” Nature 184, no. 4690 (19 September): 844–846.
Mozziconacci, Julien, Mélody Merle, and Annick Lesne. 2020. “The 3D Genome Shapes the Regulatory Code of Developmental Genes.” Journal of Molecular Biology 432, no. 3 (7 February): 721–723.
Mukai, Takahito, Marc J. Lajoie, Markus Englert, and Dieter Söll. 2017. “Rewriting the Genetic Code.” Annual Review of Microbiology 71 (July 11): 557–577.
Nelson, Celeste M. 2022. “Mechanical Control of Cell Differentiation: Insights from the Early Embryo.” Annual Review of Biomedical Engineering 24 (June 6): 307–322.
Peirce, Charles Sanders. 1987. Collected Papers of Charles Sanders Peirce. Volumes I and II: Principles of Philosophy and Elements of Logic. Edited by Charles Hartshorne and Paul Weiss, Sections 2.227–2.310. Cambridge, Massachusetts: Harvard University Press.
Polyansky, Anton A., Mario Hlevnjak, and Bojan Zagrovic. 2013. “Proteome-Wide Analysis Reveals Clues of Complementary Interactions Between mRNAs and their Cognate Proteins as the Physicochemical Foundation of the Genetic Code.” RNA Biology 10, no. 8 (August): 1248–1254.
Root-Bernstein, Robert Scott. 1982. “On the Origin of the Genetic Code.” Journal of Theoretical Biology 94, no. 4 (21 February): 895–904. Rumbley, Jon, Linh Hoang, Leland Mayne, and S. Walter Englander. 2001 “An Amino Acid Code for Protein Folding.” Proceedings of the National Academy of Sciences, USA 98, no. 1 (January 2): 105–112.
Shannon, C. E. 1948. “A Mathematical Theory of Communication.” The Bell System Technical Journal 27 (July, October): 379–423, 623–656.
Shannon, Claude E., and Warren Weaver. 1964. The Mathematical Theory of Communication. Urbana, Illinois: University of Illinois Press.
Shapiro, James A. 2017. “Biological Action in Read–Write Genome Evolution.” Interface Focus 7, no. 5 (6 October): 20160115.
Siemens, Eduard. 2022. “2. Information–Intelligenz–Wille.” https://www.youtube.com/watch?v=2uK_OYkiIB0.
Siemens, Eduard. 2023. “Information–Intelligenz–Wille: Begriff and Erkenntnisgrenzen.” https://www.youtube.com/watch?v=XnVcZT6XtdY.
Singh, Simon. 2000. The Code Book: The Science of Secrecy from Ancient Egypt to Quantum Cryptography. New York, New York: Anchor Books.
Stinson, Douglas R. 2005. Cryptography: Theory and Practice. 3rd ed. Boca Raton, Florida: Chapman and Hall/CRC.
Teufel, Felix, José Juan Almagro Armenteros, Aleander Rosenberg Johansen, Magnús Halldór Gíslason, Silas Irby Pihl, Konstantinos D. Tsirigos, Ole Winther, Søren Brunak, Gunnar von Heijne, and Henrik Nielsen. 2022. “SignalP 6.0 Predicts All Five Types of Signal Peptides Using Protein Language Models.” Nature Biotechnology 40 (3 January): 1023–1025.
Togneri, Roberto, and Christopher J. S. deSilva. 2003. Fundamentals of Information Theory and Coding Design. Boca Raton, Florida: Chapman and Hall/CRC.
Tollefsbol, Trygve O. 2022. Handbook of Epigenetics: The New Molecular and Medical Genetics. 3rd ed. New York, New York: Elsevier.
Truman, Royal. 2012a. “An Evaluation of Codes More Compact Than the Natural Genetic Code.” Journal of Creation 26, no. 2 (August): 88–99.
Truman, Royal. 2012b. “Information Theory—Part 3. Introduction to Coded Information Systems.” Journal of Creation 26, no. 3 (December): 115–119.
Truman, Royal. 2013. “Information Theory—Part 4. Fundamental Theorems of Coded Information Systems Theory.” Journal of Creation 27, no. 1 (April): 71–77.
Truman, Royal. 2016a. “Cells as Information Processors Part I: Formal Software Principles.” Creation Research Society Quarterly 52, no. 4 (Spring): 275–309.
Truman, Royal. 2016b. “Cells as Information Processors Part 2: Hardware Implementation.” Creation Research Society Quarterly 53, no. 1 (Summer): 19–41.
Varn, D. P., and J. P. Crutchfield. 2016. “What Did Erwin Mean? The Physics of Information From the Materials Genomics of Aperiodic Crystals and Water to Molecular Information Catalysts and Life.” Philosophical Transactions of the Royal Society A 374: 20150067. http://dx.doi.org/10.1098/rsta.2015.0067
Vermeulen, Katrien, Dirk R. Van Bockstaele, and Zwi N. Berneman. 2003. “The Cell Cycle: A Review of Regulation, Deregulation and Therapeutic Targets in Cancer.” Cell Proliferation 36, no. 3 (June): 131–149.
Yarus, Michael. 2017. “The Genetic Code and RNA-Amino Acid Affinities.” Life (Basel) 7, no. 2 (March 23): 13. https://doi.org/10.3390/life7020013.
Yarus, Michael, Jeremy Joseph Widmann, and Rob Knight. 2009. “RNA-Amino Acid Binding: A Stereochemical Era for the Genetic Code.” Journal of Molecular Evolution 69, no. 5 (November): 406–429.
Wiener, Norbert. 1948. Cybernetics, or Control and Communication in the Animal and the Machine. Cambridge, Massachusetts: The Technology Press.
Wiener, Norbert. 1961. Cybernetics: or Control and Communication in the Animal and the Machine. Cambridge, Massachusetts: The MIT Press.
Williams, Alex. 2005. “Inheritance of Biological Information—Part II: Redefining the ‘Information Challenge’.” TJ 19, no. 2 (August): 36–41.
Wong, J Tze-Fei, Siu-Kin Ng, Wai-Kin Mat, Taobo Hu, and Hong Xue. 2016. “Coevolution Theory of the Genetic Code at Age Forty: Pathway to Translation and Synthetic Life.” Life (Basel) 6, no. 1 (March 16): 12.
Appendix A. Can Multiple Copies of a Message Produce More Information?
A difficulty often encountered when discussing the scientific concept of information is that it is not quantitative, unlike physical sciences. Gitt believes quantification is not necessary. Another researcher agreed and called information a nominal entity (Williams 2005), noting that
By nominal we mean that information can be named (i.e. identified) but it cannot be explained in terms of matter or energy so it is a third fundamental component of the universe after matter and energy.
Truman has suggested that quantification could be attempted by measuring the effects of information. According to Coded Information Systems (CIS) logic, intended outcomes can be guided not only through the use of coded messages, but also through “other resources” such as engineered constraints, and the receiver’s ability to incorporate context and pre-loaded logic-processing abilities (Truman 2013). This explains the emphasis on a system in CIS theory instead of information.
To quantify the effect of an informational component, the range of behavior displayed by the receiving system can be compared before and afterward. The system behavior would be expressed as entropy, H, with the information provided causing the difference:
Information provided = Hbefore information–Hafter information
analogous to Shannon’s approach.
A consequence of this line of reasoning is that identical message copies can have separate but additive outcomes at different times and locations (Truman 2013). For example, one seed has an effect: it changes the distribution of matter and energy at some location when producing one tree. Multiple identical seeds can produce multiple trees, collectively reorganizing more matter and energy even though the genetic information provided by each seed was identical. These concepts were discussed in what Truman dubbed Coded Information System (CIS) theory (Truman 2012b), an effort to explain how coded messages could be leveraged with other resources. These ideas were prompted by noting that far more was being regulated in biological cells than seemed to be encoded in DNA.
Multiple copies of messages also seem capable of providing more information when each is sent to different receivers that respond differently. For example, the message,
“Protect yourself” sent to a spy, computer gamer, or woman trapped in a house fire, will result in very different behavior (pragmatics). This is expected when intelligent receivers reason before deciding what action to take. When to send the message; where; to whom; and how can produce outcomes the message alone could have accomplished.
This Appendix is intended to illustrate how opposite conclusions about information can be arrived at based on the exact premises and viewpoints used.
Appendix B. The Stereochemical Hypothesis of the Origin of the Genetic Code
A common error in the evolutionary literature violates the fundamental principle that information does not derive from the matter on or in which it is imprinted or carried. An important example involves the efforts to find a natural chemical explanation for the origin of the genetic code. The essence of these speculations is that prebiotically some amino acids might have interacted slightly better with some RNA nucleotide patterns (Polyansky et al 2013; Root-Bernstein 1982; Yarus 2017; Yarus et al 2009). Maury claimed that,
Direct chemical interaction between amino acids/peptides and ribonucleotides in the primordial environment was probably important [sic] the evolution of the genetic code. (Maury 2018, 1503)
This reveals a profound misunderstanding of how the translation of mRNA by the ribosome works in biological cells to produce protein sequences. There is no physical contact between the mRNA that communicates protein sequences and the amino acid that is to be added next! Fig. 6 shows how adaptor molecules called tRNAs execute the translation of a DNA codon → amino acid. At one end the anti-codon portion of a tRNA attaches to the counterpart codon on mRNA, and simultaneously a distant region of that tRNA must bind the intended amino acid in a reactive high-energy state.
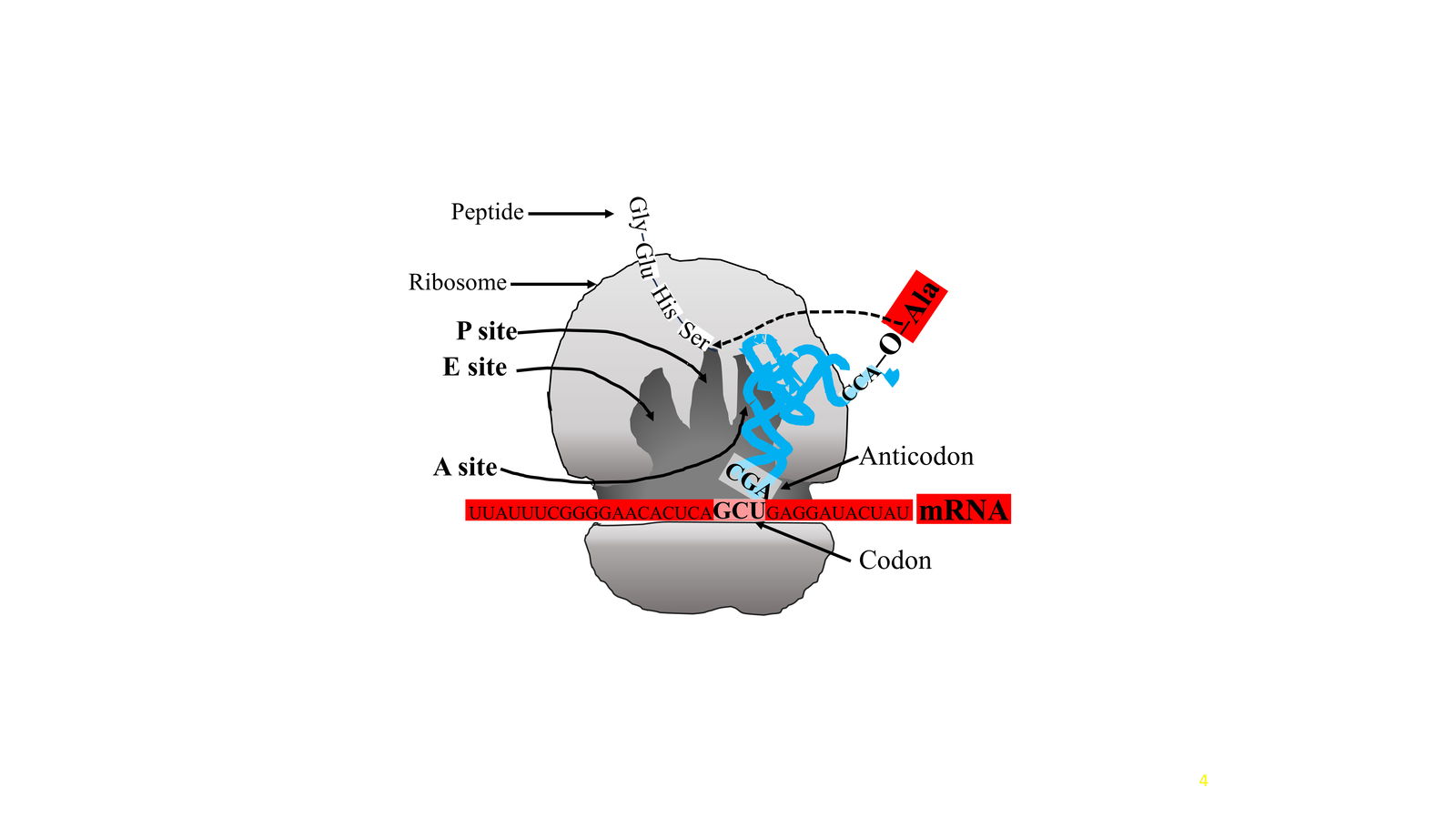
Fig. 6. Decoding mRNA codons. The anti-codon region of a tRNA interacts with an mRNA codon counterpart, specifying which amino acid to attach to the protein being formed. The process involves choreographed movements at the A, P, and E ribosomal sites. tRNA is shown in blue, mRNA in red.
To reiterate, the mRNA is always very distant from the amino acids and has no direct interaction or influence with them. Translation only works because dozens of aminoacyl-tRNA synthetase enzymes exist that “know” which amino acid to add to which tRNA with no influence from the anti-codon region (Lesne 2023; Mozziconacci, Merle, and Lesne 2020). And vice-versa, each codon of the mRNA “knows” which anti-codon to bind to with no influence from the amino acid attached at a distant location.
Stepwise translation of each codon requires repetitive processing steps at three key ribosomal locations called the A, P, and E sites, none of which involve interaction between the amino acids and mRNA.
Experiments have demonstrated that direct chemical interaction between an amino acid and a specific codon on mRNA cannot be why that amino acid is added to the end of a peptide sequence in cells. Researchers showed this by altering the nucleotide pattern in the anti-codon region on several tRNAs, while leaving the amino acids and mRNA exactly as they were before. This resulted in different peptide sequences (Mukai et al. 2017).
The genetic code provides a clear example of the independence of information from the material carrier. The meaning communicated by each codon does not have a material cause, any more than the properties of paper and ink can explain the origin of an encyclopedia.
An example might help illustrate how materialists attempt to explain the origin of the genetic code. Suppose scientists observe that symbols are attached to letters that post office technology examines, leading to letters being delivered to specific locations. Some scientists might propose that the ink forming each symbol has slightly different attractions to different locations worldwide, and the post office technologies then evolved with no intelligent guidance to produce a perfectly working code.
Appendix C. A More Compact Hypothetical Genetic Code
Four DNA nucleotides {A, C, G, T} are combined three at a time in distinct patterns to represent the 20 amino acids and a Stop signal. Baranov, Venin, and Provan 2009 expressed the very common but incorrect opinion,
The length of codons in the genetic code is also optimal, as three is the minimal nucleotide combination that can encode the twenty standard amino acids.
The intuition is that one nucleotide could only represent one amino acid, so four nucleotides taken individually could represent only four amino acids. A code using pairs of nucleotides could represent only 42 = 16 amino acids and not all 20. Triplets of nucleotides could represent up to 43 = 64 amino acids, more than enough. The mistake Baranov and others have made is to assume that the codewords must be of fixed length. However, codes like the Morse Code use different numbers of symbols to represent the letters of an alphabet. Many compact coding systems are used in computer technologies that rely on codewords of unequal lengths (Appendix D, Note 2).
Based on the Kraft Inequality (Togneri and deSilva 2003, 115–118) and McMillan’s Theorem (Togneri and deSilva 2003, 118–120) a shorter coding scheme could be devised for the genetic code, that has been demonstrated (Truman 2012a).
By assigning the most frequently used amino acids in proteins to 2-symbol codewords and the less frequently used ones to 3-symbol codewords the entire DNA in the human genome could have been decreased by more than 25% (Truman 2012a). Although the savings in space and building material would have been substantial, Truman argued that this would have required far more complex and error-prone decoding equipment (ribosomes), leading to mistranslations and more severe effects from random mutations on DNA.
This appendix draws attention to the variety of design tradeoffs to evaluate when analyzing biological codes. Natural processes lack the necessary reasoning faculties to recognize and solve these tradeoffs.
Appendix D. Notes
Note 1. The receiving decoding equipment could be affected at the point of interaction, for example by small differences in temperature for each symbol. This is especially relevant for analog computing, and a potential source of error. However, even correctly receiving a sequence of symbols would not be sufficient to decipher the message’s meaning. The suggestion is to monitor behavior after the message content has been processed. Note that this is a separate step that requires the decoding equipment to be linked to additional equipment that can implement the intention of the message.
Note 2. Several technologies are used to compress text using variable-length codewords. Examples include Huffman Coding, Lempel-Ziv-Welch (LZW) Compression, and Run-Length Encoding (RLE). The popular ZIP tool can compress long messages, that is, entire files. To illustrate, one can replace the four nucleotides with numbers. A → 0, C → 1, G → 2, T → 3. We create a new code by assigning the amino acids (aa): 00 = aa1; 01 = aa2; . . . 33 = aa14; 020 = aa15 . . . 031 = aa20; 032 = Stop. Notice that as soon as a codeword has been decoded a new codeword begins. This works since the code has a rule that the beginning of each codeword must not contain a shorter codeword. This is an instantaneous code since the decoder always “knows” when the end of a codeword is reached.
Note 3. Modern digital programming involves source code that humans can understand. The logic implemented with analog computing techniques is often difficult to understand being integrated with the hardware. Several principles and explanations were introduced in a lecture by Truman titled “Cells are integrated, parallel processing analog computing devices” on May 31, 2023 during a conference sponsored by The Institute of Creation Research.




